19/06/2026 04:56น.

ทำไม CAPTCHA ถึงให้เราพิสูจน์ว่า ฉันไม่ใช่หุ่นยนต์?
#reCAPTCHA
#ป้องกันบอท
#ฉันไม่ใช่หุ่นยนต์
#เทรน AI
#Invisible CAPTCHA
#CAPTCHA
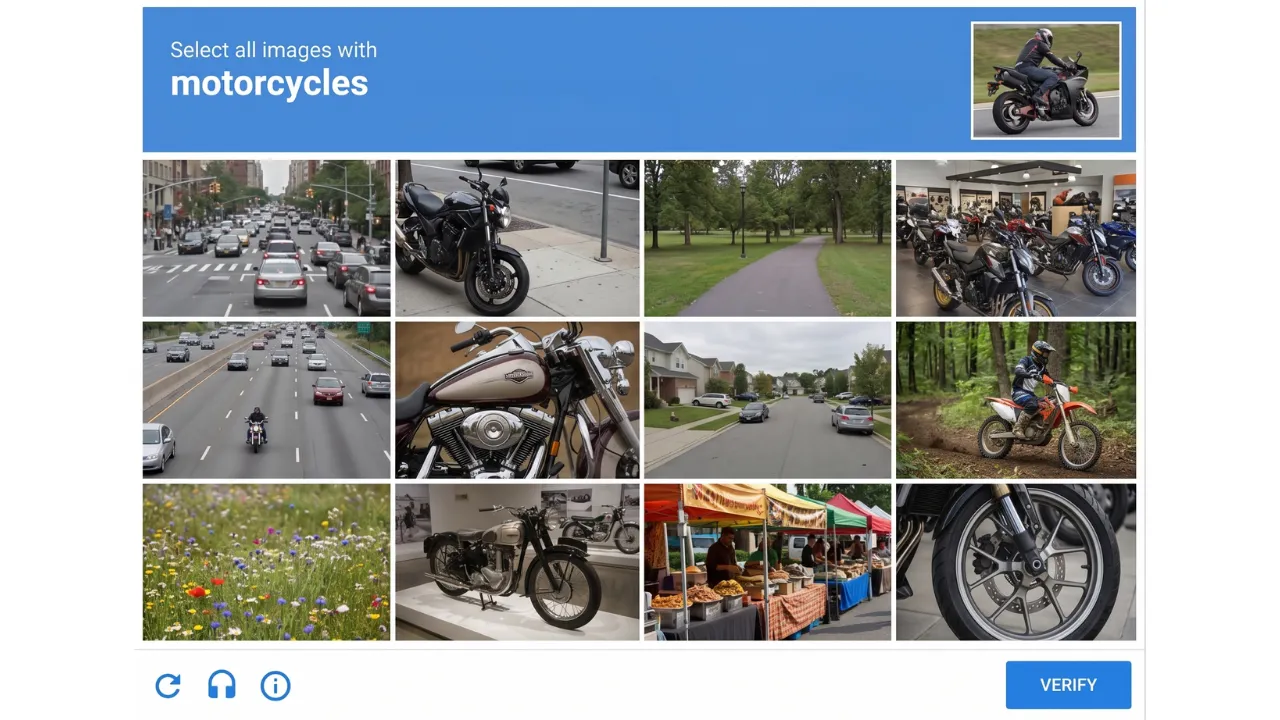
มีใครเคยเจอเหตุการณ์แบบนี้บ้างไหมครับ? กำลังจะกดตั๋วคอนเสิร์ตวงโปรดที่รอมาร่วมปี กำลังจะกดซื้อของชิ้นเด็ดในแอปช้อปปิ้งที่จัดโปรโมชันลดราคาแค่ 1 นาที หรือกำลังจะสมัครสมาชิกเว็บใดเว็บหนึ่ง แล้วทันใดนั้น... หน้าต่างเจ้ากรรมก็เด้งขึ้นมาขัดขวางพร้อมข้อความสั้นๆ แต่แทงใจดำว่า: "โปรดเลือกรูปภาพที่มีไฟจราจร" หรือ "โปรดเลือกรูปภาพที่มีทางม้าลาย"
ตัดภาพมาที่เรา... นั่งจ้องหน้าจอตากระตุก พยายามมองหาเศษเสี้ยวของเสาไฟจราจรที่แอบโผล่มาในอีกช่องหนึ่งแค่ 2 มิลลิเมตร พอตัดสินใจกดเลือกไป ระบบกลับบอกว่า "คุณเลือกไม่ถูกต้อง โปรดลองอีกครั้ง" พร้อมเปลี่ยนเป็นรูปหน้าร้านค้าหรือทางเท้าที่เบลอจนแทบแยกไม่ออก จนบางทีอดคิดในใจไม่ได้ว่า สรุปนี่เราสายตาสั้น ตาบอดสี หรือระบบมันตั้งใจแกล้งไม่ให้เราเข้าเว็บกันแน่? แล้วทำไมมนุษย์เนื้อหนังมังสาอย่างเรา ต้องมานั่งพิสูจน์ตัวเองกับหน้าจอเหลี่ยมๆ ทุกวันว่า... ฉันไม่ใช่หุ่นยนต์นะ🤖❌
เจ้าสิ่งนี้ที่เราเจอกันจนเบื่อเรียกว่า CAPTCHA ครับ แม้ว่ามันจะสร้างความหงุดหงิดให้เราอยู่บ่อยๆ แต่เบื้องหลังกล่องสี่เหลี่ยมและรูปภาพเหล่านั้น มีเทคโนโลยีการรักษาความปลอดภัยที่ล้ำลึก มีการขับเคี่ยวกันระหว่างนักพัฒนาเว็บกับแฮกเกอร์ และที่สำคัญ โลกของ CAPTCHA ในปัจจุบัน (รวมถึงปี 2026 นี้) มันเดินหน้าไปไกลกว่าที่เราคิดมาก จนบางทีเราแทบไม่ต้องขยับนิ้วเลือกรูปอีกต่อไปแล้ว
บทความนี้เราจะมาเจาะลึกแบบหมดเปลือก ว่าสรุปแล้วระบบนี้มันทำงานอย่างไร? ปุ่มติ๊กถูกทีเดียวมันรู้ได้ไงว่าเราเป็นคน? และในอนาคตเราจะหลุดพ้นจากวงจรการเลือกรูปภาพพวกนี้ได้อย่างไร มาหาคำตอบกันครับ
จุดประสงค์ที่แท้จริง
เพื่อให้เข้าใจว่าทำไมเราต้องทนกดรูปภาพเหล่านี้ เราต้องมาดูฝั่งผู้พัฒนาเว็บไซต์กันก่อนครับ เหตุผลหลักที่ทุกเว็บไซต์ต้องตั้งการ์ดสูงขนาดนี้ เป็นเพราะโลกอินเทอร์เน็ตมีสิ่งที่เรียกว่า "บอท (Bots)" หรือโปรแกรมอัตโนมัติที่คอยวิ่งพล่านไปทั่ว ถ้าเว็บไซต์เปิดประตูให้ทุกคนเข้าใช้งานได้ง่ายๆ โดยไม่มีการคัดกรอง แฮกเกอร์หรือผู้ไม่หวังดีจะสามารถส่งบอทเข้ามาป่วนเว็บได้ในระดับมหาศาล เช่น:
บอทกดบัตร (Scalping Bots): แย่งกดตั๋วคอนเสิร์ตหรือสินค้าลิมิเต็ดวินาทีละเป็นหมื่นๆ ครั้งเพื่อเอาไปรีเซลอัพราคา
บอทสแปม (Spam Bots): วิ่งไปคอมเมนต์ฝากร้านหรือลิงก์พนันตามบล็อกต่างๆ จนเว็บพัง
บอทเดารหัสผ่าน (Brute Force Attack): สุ่มพิมพ์รหัสผ่านเพื่อพยายามแฮกเข้าบัญชีผู้ใช้ด้วยความเร็วสูง
หน้าที่ของ CAPTCHA (ย่อมาจาก Completely Automated Public Turing test to tell Computers and Humans Apart) จึงทำหน้าที่เป็นเหมือน "ยามหน้าประตู" คอยถามคำถามที่มนุษย์ทั่วไปตอบได้ง่ายๆ แต่โปรแกรมคอมพิวเตอร์ในยุคก่อนตอบได้ยากนั่นเองครับ
ความจริงอีกด้าน
หลายคนอาจจะเคยสงสัยว่าทำไมโจทย์ CAPTCHA ต้องเป็นรูปทางม้าลาย รูปป้ายจราจร หรือรูปหน้าร้านค้าบ่อยจัง? ความจริงที่อิงจากข้อมูลทางเทคโนโลยีก็คือ เวลาที่เรากำลังนั่งคลิกเลือกรูปภาพเพื่อพิสูจน์ตัวเองอยู่นั้น เราไม่ได้แค่กำลังยืนยันว่าเราเป็นมนุษย์เพื่อให้ได้เข้าเว็บครับ แต่เรากำลังทำหน้าที่เป็น คนติดป้ายจำแนกข้อมูล (Data Labeler) ให้กับระบบปัญญาประดิษฐ์ (AI) ของบริษัทยักษ์ใหญ่โดยที่เราไม่รู้ตัว ยกตัวอย่างเช่น ระบบ reCAPTCHA ของ Google (เวอร์ชันที่มีกล่องข้อความและรูปภาพให้เลือก):
ยุคแรก (พิมพ์ตัวอักษรเบี้ยวๆ): ข้อมูลจริงระบุว่า Google นำภาพตัวอักษรที่สแกนมาจากหนังสือเก่าๆ หรือหนังสือพิมพ์โบราณที่ระบบคอมพิวเตอร์อ่านไม่ออก มาตัดเป็นท่อนๆ แล้วให้มนุษย์อย่างเราช่วยพิมพ์บอกว่ามันคือคำว่าอะไร เพื่อนำไปใช้ในโครงการ Google Books และดิจิทัลไฟล์เอกสารทั่วโลก
ยุคต่อมา (เลือกรูปภาพบนท้องถนน): เมื่อเข้าสู่ยุคของรถยนต์ขับเคลื่อนอัตโนมัติ (Autonomous Vehicles) และการพัฒนาระบบแผนที่ ระบบเปลี่ยนมาให้เราเลือกรูป "ทางม้าลาย ไฟจราจร รถบัส ป้ายบอกทาง หรือสะพาน" ภาพเหล่านั้นคือภาพจริงจากกล้องบนท้องถนนที่ระบบ AI ของเขายังไม่มั่นใจ 100% ว่ามันคืออะไร การที่เรากดติ๊กถูกเลือกช่องที่มีไฟจราจร จึงเป็นการส่งคำตอบไปเฉลยและ เทรน AI ให้ฉลาดขึ้น ในการแยกแยะวัตถุบนท้องถนนนั่นเอง
พูดง่ายๆ ก็คือ เว็บไซต์ได้ระบบคัดกรองบอทฟรี ส่วนค่ายเทคโนโลยีก็ได้แรงงานมนุษย์นับล้านคนทั่วโลกคอยช่วยตรวจทานและเทรน AI ให้ฟรีๆ ทุกวัน ถือเป็นดีลทางธุรกิจที่ชาญฉลาดและล้ำลึกมากครับ
เบื้องหลังปุ่ม
หลังจากยุคที่เราต้องนั่งปวดตาเลือกรูปภาพ ค่ายเทคโนโลยีก็พัฒนาต่อจนกลายมาเป็นกล่องข้อความสี่เหลี่ยมสีขาวโล่งๆ พร้อมข้อความว่า "ฉันไม่ใช่หุ่นยนต์" (I'm not a robot) ที่พอเราเอานิ้วไปจิ้ม หรือเอาเมาส์ไปคลิกทีเดียว ระบบก็ขึ้นเครื่องหมายติ๊กถูกสีเขียว ให้เราผ่านเข้าเว็บได้ทันทีภายในเวลาไม่ถึงวินาที เคยสงสัยไหมครับว่า แค่คลิกเดียว มันจะไปแยกแยะ มนุษย์ กับ หุ่นยนต์ ได้ยังไง? บอทมันก็แค่สั่งให้กดตรงพิกัดนี้เหมือนกันไม่ได้เหรอ?
คำตอบคือ ได้ครับ บอทสามารถกดตรงพิกัดนั้นได้สบายมาก แต่ความจริงที่อิงตามหลักการทำงานของระบบความปลอดภัยระดับโลก (อย่าง reCAPTCHA v2 ของ Google) ก็คือ ระบบไม่ได้สนใจผลลัพธ์ตอนคลิกเสร็จ แต่ระบบแอบเฝ้าดูพฤติกรรม (Telemetry Data) ทั้งหมดของเราก่อนที่นิ้วจะกดลงไปต่างหากครับ โดยข้อมูลจริงทางเทคนิคระบุว่า ระบบจะแอบตรวจสอบองค์ประกอบหลักๆ 3 ส่วน ดังนี้:
1. วงจรการเคลื่อนที่ของเมาส์ (Mouse Movement)
ถ้าเป็นบอท: โปรแกรมคอมพิวเตอร์จะทำงานด้วยความแม่นยำสูงสุด ตรรกะของมันคือการวาร์ปเมาส์จากจุด A ไปยังจุด B เป็นเส้นตรงดิ่งที่สั้นที่สุดด้วยความเร็วคงที่ หรือคลิกตรงพิกัดตรงเป๊ะๆ ทุกครั้ง
ถ้าเป็นมนุษย์: มนุษย์เราไม่ได้มีกล้ามเนื้อที่เสถียรขนาดนั้นครับ เวลาเราเลื่อนเมาส์ไปที่ปุ่ม เส้นทางการลากเมาส์ของเราจะมีความโค้ง มีความสั่นไหวเล็กๆ (Micro-fluctuations) มีการชะลอความเร็วลงก่อนจะถึงปุ่ม และพิกัดที่คลิกมักจะไม่ซ้ำกันเลยในแต่ละครั้ง ความ "ไม่สมบูรณ์แบบ" ของร่างกายมนุษย์นี่แหละครับ คือหลักฐานชั้นดีที่บอทเลียนแบบได้ยากมากๆ
2. ข้อมูลคุกกี้และประวัติการท่องเว็บ (Browser Cookies & History)
ก่อนที่เราจะกดปุ่มนั้น ระบบจะแอบเปิดดู "ประวัติส่วนตัว" ของเบราว์เซอร์เราแบบเงียบๆ ครับ เช่น เบราว์เซอร์นี้มีการเข้าใช้งานเว็บอื่นมาก่อนไหม? มีการล็อกอินบัญชี Gmail หรือบริการอื่นๆ ทิ้งไว้รึเปล่า? มีการเลื่อนอ่านหน้าเพจ (Scroll) เหมือนคนปกติไหม?
ถ้าประวัติขาวสะอาดเพิ่งเปิดขึ้นมาสดๆ ร้อนๆ แล้วพุ่งตรงมากดปุ่มยืนยันทันที ระบบจะเริ่มสงสัยไว้ก่อนเลยว่านี่อาจจะเป็นบอทที่แฮกเกอร์รันขึ้นมา
3. ที่อยู่ IP และพฤติกรรมเครือข่าย (Network IP & Location)
ระบบจะตรวจสอบว่าคำขอ (Request) นี้ถูกส่งมาจากไหน หากมาจากอินเทอร์เน็ตบ้านหรือสัญญาณมือถือทั่วไป ความน่าเชื่อถือจะสูงมาก แต่ถ้า IP นั้นตรงกับ Data Center (ศูนย์ข้อมูล) ที่แฮกเกอร์มักใช้รันบอท หรือมีการส่งคำขอเข้ามาถี่เกินไปในเวลา 1 วินาที ระบบจะปัดตกทันที
💡ข้อมูลตรงนี้ยังช่วยตอบคำถามที่เราสงสัยในใจด้วยครับว่า ทำไมบางทีเรากดติ๊กถูกทีเดียวแล้วผ่านเลย แต่บางทีพอกดแล้ว มันกลับเด้งหน้าต่างรูปภาพไฟจราจรมาให้เราเลือกซ้ำอีก? นั่นเป็นเพราะว่าคะแนนความน่าจะเป็น (Risk Score) ของเราในตอนนั้นต่ำเกินไป เช่น เราอาจจะกำลังเปิดใช้ VPN อยู่, เผลอเลื่อนเมาส์เร็วและตรงเกินไป หรือใช้เบราว์เซอร์ที่บล็อกคุกกี้ไว้ทั้งหมด ระบบไม่มั่นใจ 100% เลยต้องส่ง ข้อสอบสำรอง ซึ่งก็คือการเลือกรูปภาพ มาให้เราทำเพื่อยืนยันอีกรอบนั่นเองครับ
Invisible CAPTCHA
โลกหมุนไปไวมากครับ พอมารู้ตัวอีกทีในปี 2026 นี้ เพื่อนๆ สังเกตเหมือนกันไหมครับว่า หน้าต่างรูปภาพกวนใจชวนเลือกไฟจราจร หรือแม้แต่ปุ่มกล่องสี่เหลี่ยมให้เราคอยกดติ๊กถูก มันเริ่ม โผล่มาให้เราเห็นน้อยลงเรื่อยๆ ในเว็บไซต์? ทำไมถึงเป็นแบบนั้น? เหตุผลอิงตามข้อเท็จจริงทางเทคโนโลยีมีอยู่ 2 ข้อหลักๆ ครับ:
1. AI ฉลาดจนแก้โจทย์รูปภาพเก่งกว่ามนุษย์แล้ว
ในอดีต ภาพบิดเบี้ยวหรือรูปถ่ายท้องถนนเป็นเรื่องยากสำหรับคอมพิวเตอร์ แต่ในปัจจุบัน โมเดล Vision-Language AI และระบบสแกนภาพ (Computer Vision) พัฒนาไปไกลมาก งานวิจัยด้านความปลอดภัยไซเบอร์หลายแห่งระบุตรงกันว่า บอทที่ติดตั้ง AI ยุคนี้สามารถอ่านตัวอักษรเบี้ยวๆ และแยกแยะรูปภาพ CAPTCHA แบบเก่าได้แม่นยำเกือบ 100% แถมยังทำเวลาได้เร็วกว่ามนุษย์เสียอีก! กลายเป็นว่าข้อสอบแบบเดิม บอททำคะแนนเต็ม แต่มนุษย์แท้ๆ กลับสอบตกและหงุดหงิดแทน ระบบแบบเก่าจึงเริ่มไร้ประสิทธิภาพในการป้องกัน
2. การมาของระบบไร้ตัวตน (Invisible CAPTCHA)
เมื่อการบังคับให้คนมานั่งกดรูปภาพนอกจากจะกันบอทไม่ได้ดีเหมือนเดิมแล้ว ยังทำให้ผู้ใช้งานหงุดหงิดจนกดปิดเว็บหนี (เสีย UX หรือ User Experience ที่ดี) นักพัฒนาจึงเปลี่ยนมาใช้เทคโนโลยีใหม่ล่าสุดอย่าง reCAPTCHA v3 ของ Google หรือระบบ Turnstile ของ Cloudflare
เทคโนโลยีเหล่านี้ทำงานอยู่เบื้องหลังแบบ 100% (Invisible) โดยที่หน้าเว็บจะไม่มีกล่องข้อความหรือรูปภาพใดๆ โผล่มาขัดจังหวะเราเลยแม้แต่ปุ่มเดียว ระบบจะใช้วิธี ประเมินคะแนนความเสี่ยง (Risk Score) จากพฤติกรรมการเลื่อนหน้าจอ ความเร็วในการพิมพ์ และการเชื่อมต่อเครือข่ายของเราอย่างเงียบๆ ตั้งแต่ก้าวแรกที่เรากดเข้ามาในเว็บ
ถ้าคะแนนของเราดูเป็นมนุษย์ปกติ (ทำตัวน่าเชื่อถือ) ประตูเว็บไซต์จะเปิดให้เราเข้าใช้งาน กดสั่งซื้อของ หรือสมัครสมาชิกได้ทันทีโดยไม่มีอะไรมากวนใจ
ระบบจะทำงานก็ต่อเมื่อตรวจพบพฤติกรรมที่ดูคล้ายบอทจริงๆ เท่านั้น ถึงจะยอมส่งคำถามมาท้าทาย

3. เทคโนโลยี Private Access Tokens (PATs)
นอกจากนี้ค่ายยักษ์ใหญ่อย่าง Apple, Google และ Microsoft ยังจับมือกันผลักดันระบบที่เรียกว่า Private Access Tokens (PATs) บนสมาร์ตโฟนและคอมพิวเตอร์ยุคใหม่ ซึ่งระบบนี้เครื่องของเรา (เช่น iPhone หรือ Android) จะทำการยืนยันกับเว็บไซต์ให้โดยอัตโนมัติเลยว่า "เฮ้! อุปกรณ์เครื่องนี้ผ่านการปลดล็อกด้วยใบหน้า (Face ID) หรือลายนิ้วมือโดยมนุษย์เจ้าของเครื่องมาเรียบร้อยแล้วนะ" เว็บไซต์ปลายทางก็จะเชื่อใจในความปลอดภัยนี้ และปล่อยให้เราผ่านเข้าใช้งานได้ทันทีโดยไม่ต้องผ่านด่าน CAPTCHA ใดๆ อีกเลยครับ เรียกได้ว่าในปัจจุบัน เทคโนโลยีรักษาความปลอดภัยกำลังขยับไปสู่จุดที่ปลอดภัยแต่ลื่นไหล ปล่อยให้ระบบหลังบ้านคุยกันเอง โดยไม่ต้องรบกวนเวลาชีวิตของมนุษย์อีกต่อไปครับ
FAQ ยอดฮิตเกี่ยวกับ CAPTCHA
ทำไมบางครั้งเราเลือกรูปภาพถูกต้องตามสั่งทุกช่องแล้ว แต่ระบบก็ยังบอกว่าเราผิด และบังคับให้เลือกรูปใหม่ซ้ำๆ?
ข้อเท็จจริง: มักไม่ได้เกิดจากคุณเลือกรูปผิดครับ แต่เกิดจาก คะแนนความน่าสงสัย (Risk Score) ของคุณในขณะนั้นสูงเกินไป เช่น คุณอาจจะกำลังเปิดใช้งาน VPN ที่แชร์ IP ร่วมกับคนอื่นเป็นร้อยเป็นพันคน หรือเบราว์เซอร์ของคุณมีการบล็อกสคริปต์/บล็อกคุกกี้ไว้ทั้งหมด ทำให้ระบบตรวจจับพฤติกรรมเมาส์และประวัติของคุณไม่ได้ เมื่อระบบ "ไม่มั่นใจ" มันจึงแกล้งส่งบททดสอบมาให้คุณทำซ้ำๆ เพื่อหน่วงเวลาและตรวจสอบแพทเทิร์นการคลิกเพิ่มเติมให้มั่นใจนั่นเอง
ในปัจจุบัน AI สามารถแก้โจทย์ CAPTCHA ได้เก่งกว่ามนุษย์จริงไหม?
ข้อเท็จจริง: จริงครับ อ้างอิงจากงานวิจัยด้านความปลอดภัยไซเบอร์ระดับโลกหลายชิ้นระบุว่า ปัจจุบันโมเดล Vision Language AI ที่ถูกพัฒนาขึ้นมา สามารถจำแนกรูปภาพ สแกนวัตถุ และอ่านตัวอักษรที่บิดเบี้ยวได้แม่นยำเกิน 96-99% (ซึ่งสูงกว่าค่าเฉลี่ยของมนุษย์ปกติที่มักจะตาเบลอและเลือกผิด) นี่จึงเป็นเหตุผลว่าทำไม CAPTCHA แบบเดิมๆ ถึงกำลังถูกยกเลิกใช้งาน เพราะมันกันบอทยุคใหม่ไม่ได้แล้ว แต่กลับสร้างความรำคาญให้มนุษย์แทน
การที่เรากดยืนยัน CAPTCHA บ่อยๆ หรือปล่อยให้ระบบแอบดูพฤติกรรม ข้อมูลส่วนตัวของเราจะรั่วไหลไหม?
ข้อเท็จจริง: แบรนด์ยักษ์ใหญ่อย่าง Google (reCAPTCHA) หรือ Cloudflare (Turnstile) มีมาตรฐานการคุ้มครองข้อมูลส่วนบุคคลที่เข้มงวด (เช่น GDPR) ข้อมูลที่ระบบเก็บไปวิเคราะห์จะเป็นเพียงข้อมูลเชิงพฤติกรรมบนหน้าเว็บ เช่น การเคลื่อนไหวของเมาส์, ข้อมูลอุปกรณ์ (User Agent), ภาษาที่ใช้, แหล่งที่มาของ IP และคุกกี้เพื่อยืนยันตัวตนเท่านั้น ระบบไม่ได้เข้าถึงข้อมูลส่วนตัวเชิงลึก เช่น รหัสผ่าน หรือเลขบัตรเครดิตของคุณ จึงสบายใจได้ในระดับหนึ่งครับ
Private Access Tokens (PATs) ที่บอกว่าจะมาแทน CAPTCHA มันปลอดภัยจริงไหม?
ข้อเท็จจริง: ปลอดภัยสูงมากและเป็นมิตรกับผู้ใช้ที่สุดครับ เพราะมันเป็นการเปลี่ยนผ่านจากการให้ "มนุษย์มานั่งแก้โจทย์" ไปเป็นการให้ "ฮาร์ดแวร์ที่ปลอดภัยช่วยยืนยัน" โดยสมาร์ตโฟนของคุณจะส่งโทเค็นรหัสลับที่ระบุว่า อุปกรณ์เครื่องนี้ผ่านการตรวจสอบและปลดล็อกด้วยระบบชีวมาตร (Face ID/Touch ID) โดยมนุษย์แล้ว ไปให้เว็บไซต์ ซึ่งกระบวนการนี้จะไม่มีการส่งข้อมูลใบหน้าหรือลายนิ้วมือของคุณออกไปนอกเครื่องเลย เว็บไซต์รู้แค่ว่าเครื่องนี้เป็นของมนุษย์จริง แล้วให้ผ่านทันที
ถ้าในอนาคต แฮกเกอร์พัฒนาบอทให้เลียนแบบการขยับเมาส์และการพิมพ์ของมนุษย์ได้ 100% ระบบจะรับมืออย่างไร?
ข้อเท็จจริง: วงการความปลอดภัยไซเบอร์จะขยับไปใช้ระบบที่เรียกว่า Behavioral Biometrics (การตรวจจับพฤติกรรมเชิงลึกตลอดเซสชัน) ครับ คือระบบจะไม่ตรวจแค่ตอนคลิกเข้าเว็บ แต่จะเฝ้าดูพฤติกรรมตลอดการใช้งาน เช่น จังหวะการพิมพ์คีย์บอร์ดหนักเบา น้ำหนักการลากนิ้วบนหน้าจอทัชสกรีน หรือเปลี่ยนไปเน้นการเข้ารหัสฝั่งฮาร์ดแวร์ร่วมกับเบราว์เซอร์ ซึ่งเป็นสิ่งที่โปรแกรมบอทจะเลียนแบบได้ยากขึ้นไปอีกขั้น
สรุป
จากที่เราเคยคิดว่ามันถูกสร้างขึ้นมาเพื่อกลั่นแกล้งหรือจับผิดเรา แต่ความจริงแล้ว CAPTCHA คือหนึ่งในฮีโร่หลังบ้านที่ช่วยปกป้องระบบอินเทอร์เน็ตให้ปลอดภัยจากการโจมตีของบอทนับล้านๆ ตัวในแต่ละวัน และที่น่าทึ่งที่สุดก็คือ สิ่งที่ใช้พิสูจน์ความเป็นมนุษย์ของเรา กลับไม่ใช่ความเก่งกาจหรือความแม่นยำทางคณิตศาสตร์ แต่เป็นความไม่สมบูรณ์แบบของเราต่างหาก ไม่ว่าจะเป็นการลากเมาส์ที่สั่นไหว การตัดสินใจที่ล่าช้า หรือสายตาที่อาจจะมองพลาดไปบ้าง สิ่งเหล่านี้คือเอกลักษณ์เฉพาะตัวที่หุ่นยนต์คอมพิวเตอร์เลียนแบบได้ยากที่สุด
และถึงแม้ว่าเทคโนโลยีในปัจจุบัน (รวมถึงปี 2026 นี้) กำลังจะทำให้ CAPTCHA ค่อยๆ จางหายไปและกลายเป็นระบบไร้ตัวตน (Invisible) ที่ทำงานอยู่เบื้องหลัง แต่เชื่อว่า "ตำนานการนั่งหาไฟจราจรและทางม้าลาย" จะยังคงเป็นประสบการณ์ร่วมที่คนในยุคอินเทอร์เน็ตทุกคนไม่มีวันลืมแน่นอนครับ